GUI and generator of the best compression parameters for perspective compressors: BSC and Kanzi. BSC is a high performance file compressor based on lossless, block-sorting data compression algorithms. Multiple algorithms that allows software fine-tuning for maximum speed or compression efficiency. Kanzi is a modern, modular, portable and efficient lossless data compressor implemented in C++. Modern: state-of-the-art algorithms are implemented and multi-core CPUs can take advantage of the built-in multi-threading. Modular: entropy codec and a combination of transforms can be provided at runtime to best match the kind of data to compress. Unlike the most common lossless data compressors, Kanzi uses a variety of different compression algorithms and supports a wider range of compression ratios as a result. Most usual compressors do not take advantage of the many cores and threads available on modern CPUs. Kanzi is multithreaded by design and uses several threads by default to compress blocks concurrently.
Скачать Ultra Compression Params Generator 1.02 (8 Mb):
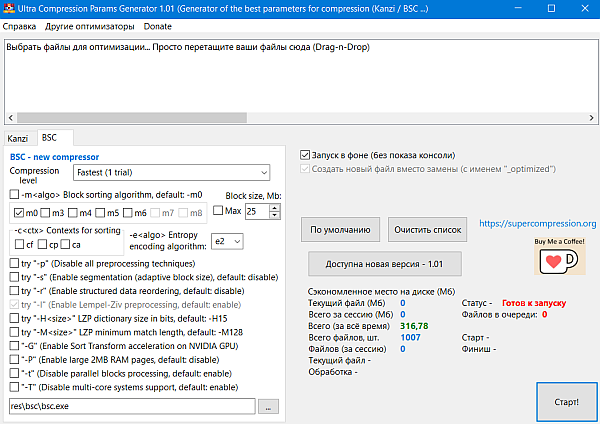
BSC is a high performance file compressor based on lossless, block-sorting data compression algorithms.
Copyright (c) 2009-2024 Ilya Grebnov
See file AUTHORS for a full list of contributors.
More info about BSC available at
Features:
The source code is available under Apache License Version 2.0.
GPU acceleration using NVIDIA CUDA technology.
64 bit and multi-core systems support.
Highly optimized code and C++ interface for superior performance.
Multiple algorithms that allows software fine-tuning for maximum speed or compression efficiency.
CRC-32 calculation routine for data integrity verification.
In-place compression and decompression to save memory.
Block sorting algorithm:
-m0 — Burrows Wheeler Transform
-m3..8 — Sort Transform of order n.
Contexts for sorting:
-cf Following contexts
-cp Preceding contexts
-ca Autodetect (experimental)
Entropy encoding algorithm:
-e0 Fast Quantized Local Frequency Coding
-e1 Static Quantized Local Frequency Coding
-e2 Adaptive Quantized Local Frequency Coding (best compression)
Preprocessing options:
-p Disable all preprocessing techniques
-s Enable segmentation (adaptive block size), default: disable
-r Enable structured data reordering, default: disable
-l Enable Lempel-Ziv preprocessing, default: enable
-H
-M
Platform specific options:
-G Enable Sort Transform acceleration on NVIDIA GPU, default: disable
-P Enable large 2MB RAM pages, default: disable
-t Disable parallel blocks processing, default: enable
-T Disable multi-core systems support, default: enable
Memory usage:
bsc compresses large files in blocks. Multiple blocks can be processed in parallel on multiple-core CPU. At decompression time, the block size used for compression is read from the header of the compressed file. The block size and number of blocks processed in parallel affects both the compression ratio achieved, and the amount of memory needed for compression and decompression. Compression and decompression requirements are the same and in bytes, can be estimated as 16Mb + 5 x block size x number of blocks processed in parallel.
GPU memory usage for NVIDIA CUDA technology is different from CPU memory usage and can be estimated as 20 x block size for ST, 21 x block size for forward BWT and 7 x block size for inverse BWT.
——————————————————————
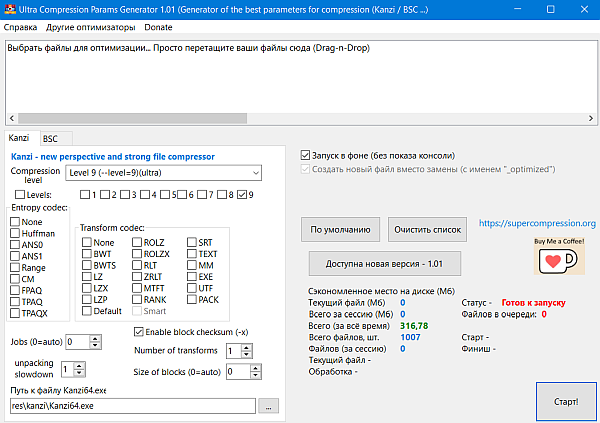
Kanzi is a modern, modular, portable and efficient lossless data compressor implemented in C++.
Kanzi 2.3 (c) Frederic Langlet
Credits: Matt Mahoney, Yann Collet, Jan Ondrus, Yuta Mori, Ilya Muravyov,
Neal Burns, Fabian Giesen, Jarek Duda, Ilya Grebnov
More info about Kanzi available at
modern: state-of-the-art algorithms are implemented and multi-core CPUs can take advantage of the built-in multi-threading.
modular: entropy codec and a combination of transforms can be provided at runtime to best match the kind of data to compress.
portable: many OSes, compilers and C++ versions are supported (see below).
expandable: clean design with heavy use of interfaces as contracts makes integrating and expanding the code easy. No dependencies.
efficient: the code is optimized for efficiency (trade-off between compression ratio and speed).
Unlike the most common lossless data compressors, Kanzi uses a variety of different compression algorithms and supports a wider range of compression ratios as a result. Most usual compressors do not take advantage of the many cores and threads available on modern CPUs (what a waste!). Kanzi is multithreaded by design and uses several threads by default to compress blocks concurrently. It is not compatible with standard compression formats.
Kanzi is a lossless data compressor, not an archiver. It uses checksums (optional but recommended) to validate data integrity but does not have a mechanism for data recovery. It also lacks data deduplication across files. However, Kanzi generates a bitstream that is seekable (one or several consecutive blocks can be decompressed without the need for the whole bitstream to be decompressed).
There are a few scenarios where Kanzi could be a better choice:
gzip, lzma, brotli, zstd are all LZ based. It means that they can reach certain compression ratios only. Kanzi also makes use of BWT and CM which can compress beyond what LZ can do.
These LZ based compressors are well suited for software distribution (one compression / many decompressions) due to their fast decompression (but low compression speed at high compression ratios). There are other scenarios where compression speed is critical: when data is generated before being compressed and consumed (one compression / one decompression) or during backups (many compressions / one decompression).
Kanzi has built-in customized data transforms (multimedia, utf, text, dna, …) that can be chosen and combined at compression time to better compress specific kinds of data.
Kanzi can take advantage of the multiple cores of a modern CPU to improve performance
It is easy to implement a new transform or entropy codec to either test an idea or improve compression ratio on specific kinds of data.
The Block compressor cuts the input file into blocks (the size can be provided on the command line with the ‘block’ option up to 1GB). Optionally, a checksum for the chunk of data can be computed and stored in the output.
As a first step, it applies one or several transforms (default is BWT+MTFT+ZRLT) to turn the block into a smaller number of bytes. Up to 8 transforms can be provided. EG: BWT+RANK+ZRLT.
As a second step, entropy coding is performed (to turn the block into a smaller number of bits).
Available transforms:
BWT: Burrows Wheeler Transform (https://en.wikipedia.org/wiki/Burrows-Wheeler_transform) is a transform that reorders symbols in a (reversible) way that is more amenable to entropy coding. This implementation uses a linear time foward transform and parallel inverse tranform.
BWTS: Burrows Wheeler Transform by Scott is a bijective variant of the BWT (slower).
LZ: Lempel Ziv (https://en.wikipedia.org/wiki/LZ77_and_LZ78). An implementation of the dictionary based LZ77 transform that removes redundancy in the data.
LZX: Lempel Ziv Extra. Same as above with a bigger hash table and/or extra match checks.
RLT: Run Length Transform (https://en.wikipedia.org/wiki/Run-length_encoding). A simple transform that replaces runs of similar symbols with a compact representation.
ZRLT: Zero Run Length Transform. Similar to RLT but only processes runs of 0. Usually used post BWT.
MTFT: Move-To-Front Transform (https://en.wikipedia.org/wiki/Move-to-front_transform). A transform that reduces entropy by assigning shorter symbols to recent data (works like a LRU cache). Usually used post BWT.
RANK: Rank Transform: A transform that that reduces entropy by assigning shorter symbols based on symbol frequency ranks. Usually used post BWT.
EXE: A transform that reduces the entropy of executable files (X86 & ARM64) by replacing relative jump addresses with absolute ones.
TEXT: A text transform that uses a dictionary to replace common words with their index.
ROLZ: Reduced Offset Lempel Ziv. An implementation of LZ that replaces match offsets with indexes of match offsets. It yields a more compact output at the cost of an extra indirection (hence slower decoding speeds).
ROLZX: Extended ROLZ with more match searches and a more compact encoding.
SRT: Sorted Rank Transform: A transform that that reduces entropy by assigning shorter symbols based on symbol frequency ranks. Usually used post BWT.
LZP: Lempel Ziv Prediction can be described as an LZ implementation with only one possible match (hence the offset is not even emitted). It is pretty weak (but fast) and usually used prior to a BWT to remove some redundancy and speed up coding.
MM: Mutimedia transform is a fast transform that removes redundancy in correlated channels in some multimedia files (EG. wav, pnm).
UTF: a fast transform replacing UTF-8 codewords with aliases based on frequencies.
PACK: a fast transform replacing unused symbols with aliases based on frequencies.
Entropy codecs.
Several entropy codecs have been implemented (sorted by increasing compression):
Huffman: The codec is a fast canonical Huffman implementation. Both encoder and decoder use tables to compute code lengths and values instead of a tree (for speed purpose).
RANGE: A fast implementation that uses pre-computed block statistics.
ANS: Based on Range Asymmetric Numeral Systems by Jarek Duda (specifically an implementation by Fabian Giesen). Works in a similar fashion to the Range encoder but uses only 1 state (instead of bottom and range) and does encoding in reverse byte order.
FPAQ: A binary arithmetic codec based on FPAQ1 by Matt Mahoney. Uses a simple, adaptive order 0 predictor based on frequencies. Fast and compact code.
CM: A binary arithmetic codec derived from BCM by Ilya Muravyov. Uses context mixing of counters to generate a prediction. Efficient and decently fast.
TPAQ: A binary arithmetic codec based initially on Tangelo 2.4 (itself derived from FPAQ8). Uses context mixing of predictions produced by one layer neural networks. The initial code has been heavily tuned to improve compression ratio and speed. Slowest but usually best compression ratio.
Compression levels:
0 = NONE&NONE (store)
1 = PACK+LZ&NONE
2 = PACK+LZ&HUFFMAN
3 = TEXT+UTF+PACK+MM+LZX&HUFFMAN
4 = TEXT+UTF+EXE+PACK+MM+ROLZ&NONE
5 = TEXT+UTF+BWT+RANK+ZRLT&ANS0
6 = TEXT+UTF+BWT+SRT+ZRLT&FPAQ
7 = LZP+TEXT+UTF+BWT+LZP&CM
8 = EXE+RLT+TEXT+UTF&TPAQ
9 = EXE+RLT+TEXT+UTF&TPAQX
———————————————————————-
Подробная статистика — отображается сэкономленное место на диске (Мб) за всё время работы и для каждого файла отдельно в списке файлов. Количество сжатых файлов, шт. (всего и за текущую сессию). Файлов в очереди, шт. (количество) (Сохраняйте файлы «res\size.txt» и «res\numbers.txt» перед обновлением, если хотите сохранить свою общую статистику по файлам и по сэкономленному месту на диске за всё время).
Программа сожмёт ваш файл с новым именем «_optimized» на конце (исходный файл останется нетронутым).
Все сообщения об ошибках и предложения шлите на maxcompress@ya.ru с темой «Ultra Compression Params Generator»
Запускайте одновременно только 1 экземпляр программы!
Программа бесплатна для коммерческого и некоммерческого использования!
Если вам понравилась программа и вы бы хотели отблагодарить автора и ускорить выход новых версий, вы можете это сделать на этой страничке.
Icon made by Swifticons from Flaticon:
https://www.flaticon.com/authors/swifticons
Disclaimer: use at your own risk. Always keep a copy of your original files!
История изменений:
2024-11-25
Ultra Compression Params Generator 1.02
-новые опции для Kanzi:
-добавлены умные режимы для быстрого подбора максимального сжатия (на основе заранее сделанных тестов);
-максимальное количество трансформ увеличено с 3 до 5;
-добавлена опция «Лимит времени распаковки, сек» (для быстрой распаковки);
-добавлена опция «Выбрать всё» для трансформ;
-добавлены быстрые тесты (итоговое сжатие будет хуже, но заметно быстрее)
2024-05-05 — 1.01
— Первый публичный релиз.
Скачать Ultra Compression Params Generator 1.02 (8 Mb):